Rhythm-controllable Speech Synthesis
Brief Introduction of My Work
The attentional mechanism in end-to-end speech synthesis affects the alignment between text and acoustic feature frames. Meanwhile it is critical for robustness issues, such as repetition, skipping, and attention collapse, as well as improvement of rhythm. With the development of speech synthesis applications, people have higher requirements on the robustness and control ability of speech synthesis systems.
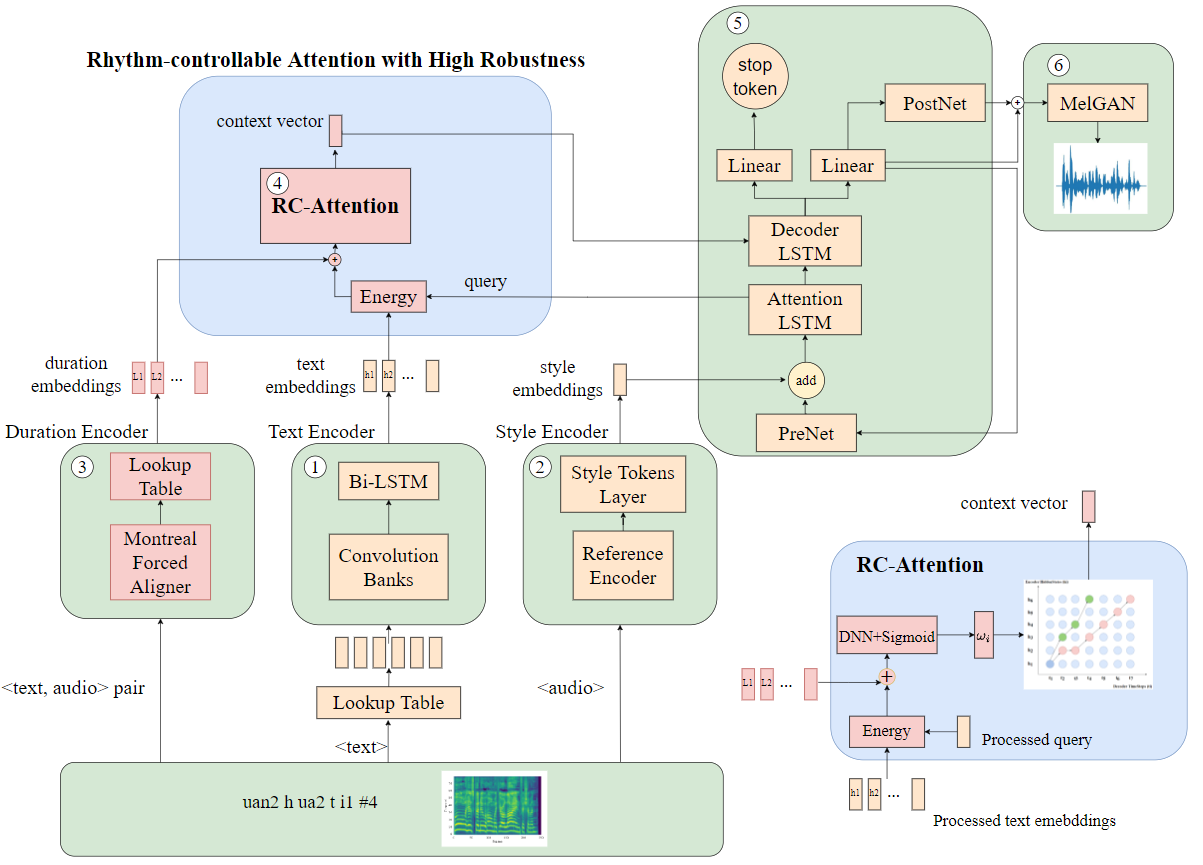
Therefore, from aspects of the robustness and controllability, I puts forward a novel attention mechanism, called RC-Attention, to improve the robustness of speech synthesis system, at the same time achieve the rhythm of external control. Specifically, in terms of robustness, the proposed attention algorithm guarantees monotonically increasing alignment and only focuses on one encoder hidden vector at most in each decoding time step. In terms of prosodic control, the proposed attention mechanism introduces additional external rhythm information to participate in alignment calculation, to achieve Fine-grained prosodic control, thus promoting the prosodic naturalness and stylistic expression of synthetic speech. The overall model was extended based on the end-to-end speech synthesis framework Tacotron2, and experiment was conducted using a self-built corpus.
Click here to know more
Current end-to-end speech synthesis systems have the ability to generate high-quality and human-like speech. Hence, speech synthesis application scenarios are becoming more and more diversified. All of these scenarios have two basic demands on synthesis systems. Firstly, speech corresponding to text can be synthesized accurately and does not exist repetition, skipping, or gibberish. This demand focuses on the robustness of synthesis system. Secondly, in addition to accuracy, people would expect synthesized speech is capable of generating natural rhythm of human. This demand focuses on model’s ability of modeling and controlling of rhythm. Both of demands can be satisfied by a well-designed attention mechanism.
The problems of robustness in speech synthesis arise from extremely unequal length between text sequence and acoustic feature sequence. In the process of upsampling, if mapping relationship from text sequences to acoustic feature sequences, named alignment matrix, is not learned well, two types of alignment problems are likely to occur. One is attention collapse which will lead to gibberish. The other is blurred alignment which means acoustic model fails to focus on a single input token in a decoding step, leading to skipping and repeating.
Some studies propose robust attention mechanisms in order to alleviate difficulty of alignment learning and accumulation of errors in the inference stage. Raffel et al. propose Monotonic Attention. The core idea is that when decoding the current timestep, model only needs to decide whether to focus on the current phoneme or move the focus forward. However, completeness of alignment cannot be satisfied, which may lead to skipping. He et al. propose Stepwise Monotonic Attention based on Monotonic Attention. By adding a constraint of forward stride to monotonic attention, the method ensures that each phoneme can be covered by at least one frame of mel spectrogram. Another novel attention is propoesd by Graves et al. , named GMM Attention which uses multiple mixed Gaussian distributions to model alignment. Meanwhile, in order to make sure monotonicity, the mean value of mixed Gaussian is constrained to increase as decoding time goes by. Many speech synthesis systems use these attentions to speed up converge of training and improve robustness of synthesis .
Methods of rhythm control are investigated by a few studies. For example, Zhang et al. propose a forward algorithm, named Forward Attention which contains a transition agent to achieve rhythm control. However, robustness may be damaged after adding the external rhythm control agent. In the inferring phase, adjusting value of transition agent by human may leads to accumulation of errors.
Therefore, in this work, we combine advantages of these attentions and propose a novel attention mechanism, called Rhythm-controllable Attention (RC-Attention), to satisfy demands of robustness and rhythm control. Proposed attention mechanism can improve robustness compared with other advanced attention mechanisms, especially in long sentences synthesis, meanwhile utilizing external duration information to synthesize speech with more natural rhythm.
Let’s begin from Attention Mechanisms
Why Study Attention Mechanisms?
The impact of attention alignment algorithms can be divided into three aspects: robustness of the synthesis system, expression of rhythmic patterns, and model convergence speed, among others.
Firstly, in terms of robustness, applications involving human-machine interaction such as intelligent robots and smart homes have high requirements for the robustness of speech synthesis systems. They expect the synthesized audio to remain coherent and fluent even in extreme boundary cases. However, even with the use of large-scale training data for synthesizing systems, some extreme boundary cases can still arise during actual application. For example, during speech synthesis training, the average length of the training data may be 14 characters, but the synthesis stage requires synthesizing text of 200 characters. Speech synthesis systems with poor robustness tend to produce phenomena such as repetition, skipped words, and incoherent speech, known as synthesis robustness issues. Designing effective attention mechanisms to enhance the alignment of text-to-speech features can effectively improve the robustness of the synthesis system.
Secondly, in terms of expressing rhythmic patterns, attention alignment influences the rhythm and prosody of synthesized speech. By using attention, control over the rhythm and prosody of the synthesized speech can be achieved, thereby enhancing its naturalness and conveying higher-level non-semantic information such as emotion, style, or intent. Due to diverse applications and market development, the demands for synthesized speech have been increasing. In addition to ensuring fluency and audio quality, there is a need for synthesized speech with rich rhythms and multiple styles. Speech synthesis systems with diverse rhythms and styles can be applied in various scenarios such as virtual assistants, call centers, voiceovers for movies and games, smart homes, narration of audiobooks, and online education. In audiobooks, synthesizing emotionally appropriate speech that aligns with the contextual context of the text can enhance the rendering power of the content. In smart homes or intelligent voice assistants like Xiaodu or Xiaobing, applying emotional synthesis technology enables machines to exhibit human-like emotions, providing various intelligent and convenient functions to users. In online education applications, such as computer-assisted teaching of Chinese as a foreign language, intonation and rhythm in pronunciation can help learners grasp key points better, enhancing memory and comprehension of knowledge.
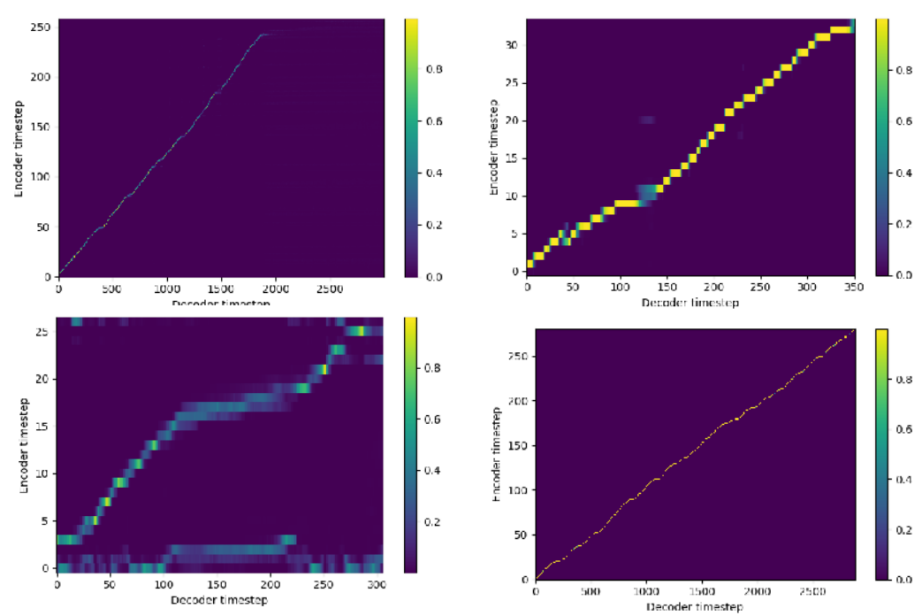
Lastly, in terms of training convergence speed, different attention mechanisms exhibit significant differences in the speed of alignment convergence. Accelerating the convergence speed helps save training time costs and energy consumption. For example, compared to the Location-sensitive Attention, the GMMv2b attention mechanism can achieve faster convergence speed, resulting in better accuracy and fluency of synthesized speech within the same number of training steps.
In summary, research on attention-based alignment algorithms holds significant value and importance. They play an important role in improving the robustness of synthesis systems, accelerating convergence speed, and enhancing the expression of rhythmic patterns in synthesized speech. Moreover, it has become a major research focus in the field of speech synthesis in recent years.。
Example of Synthesized samples
Proposed attention mechanism can improve robustness compared with other advanced attention mechanisms, especially in long sentences synthesis
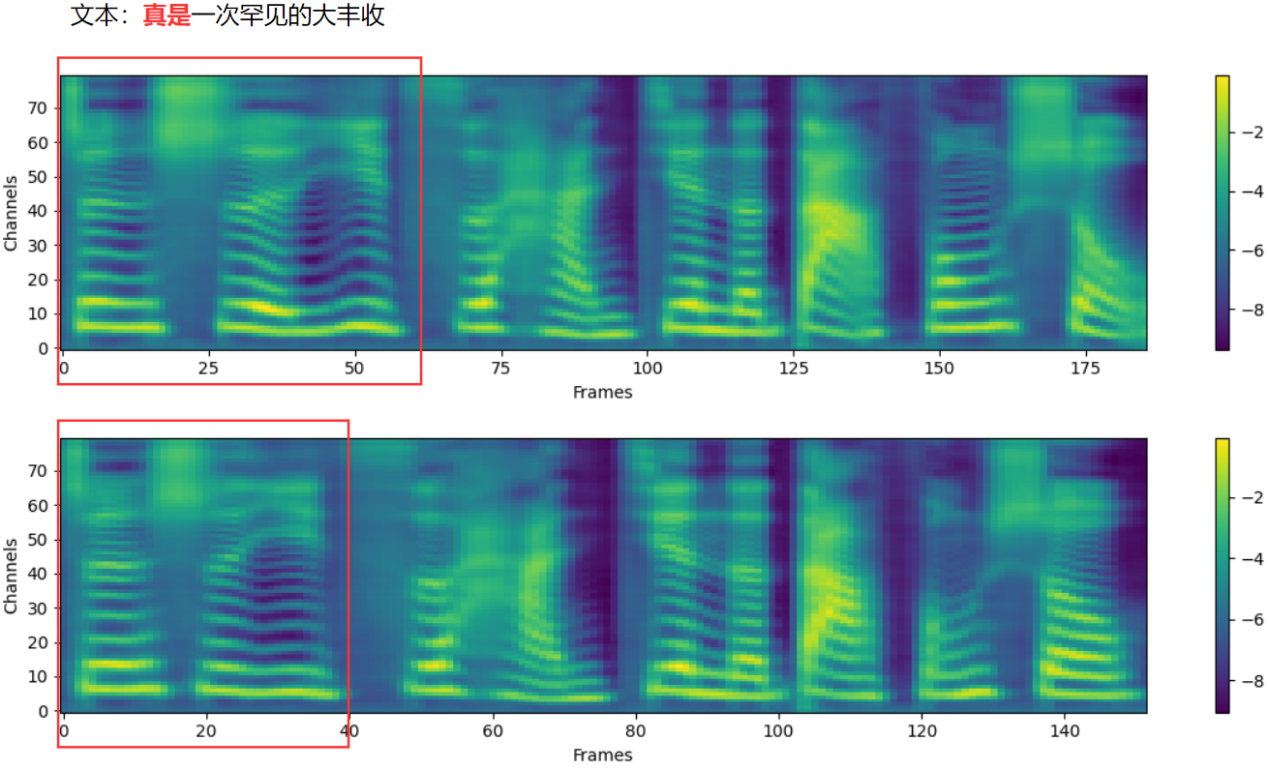
The complex sentences used in this experiment were selected from recent press releases. Each sentence contains an average of 147 Chinese characters, which is considered lengthy compared to the average length of 14 characters in the training text.
- Left: Baseline
- Right: Proposed
Proposed attention mechanism utilizs external duration information to synthesize speech with more natural rhythm.
Self-Built Corpus
The related validation experiment is conducted based on a self-built emotional corpus, which includes four types of emotional tags: happiness, anger, neutrality, and sadness. If you are interested in my corpus, please feel free to reach out to me via email.
| Emotion | Size | Example |
|---|---|---|
| neutral | 2334 | 眼中光芒强盛,看向对面的两个孩子时 |
| happy | 2334 | 眼中射出两道光束 |
| angry | 2332 | 镇中的人闻言,全都变色 |
| sad | 2332 | 从开始到现在,数次大战这个山村的孩子 |
Vedio
If you wish to delve into more details, I recommend you to watch the detailed introduction video below, or click on the link to read the original academic paper.
Enjoy Reading This Article?
Here are some more articles you might like to read next: