Conversational Speech Synthesis
Project Background
With the significant advancements in computer technologies such as signal processing, natural language processing, and speech synthesis, the progression of speech synthesis technology has been greatly propelled. Modern speech synthesis can now generate speech with a naturalness that is close to human level. Although many models have been developed for synthesizing reading styles or highly expressive speech, achieving good quality, these models are largely based on standard speech corpora recorded in controlled environments, such as reading or performing. As a result, they lack the ability to express colloquial speech in real-world scenarios. Therefore, the generation of naturally colloquial speech and the enhancement of the naturalness and authenticity of synthesized speech have become hot topics for researchers.
Conversational Speech Synthesis
Conversational speech synthesis aims to produce speech that is appropriate for oral communication situations. The existing Text-to-Speech (TTS) technology still falls short in delivering satisfactory performance and immersive experiences in dialogue-oriented tasks due to the following challenges:
- an effective method of developing a conversational speech corpus
- a high performance TTS model of capturing rich prosody in conversations
My work primarily focuses on addressing the second challenge.
I am endeavoring to investigate effective methods to bolster the capabilities of context modeling and comprehension. This is to ensure that the speech synthesis model can accurately generate context-appropriate emotions and prosody.
Context Modeling and Comprehension
Due to the diverse prosody naturally conveying paralinguistic information, including subtle emotions. Hence, how to utilize dialogue context information to enhance the naturalness of the prosody in synthesized speech under spontaneous expression is also a major research focus for scholars.
Privious studies have shown that context information modeling in conversational text-to-speech (CTTS) makes a great improvement towards prosody and naturalness of synthesized speech.
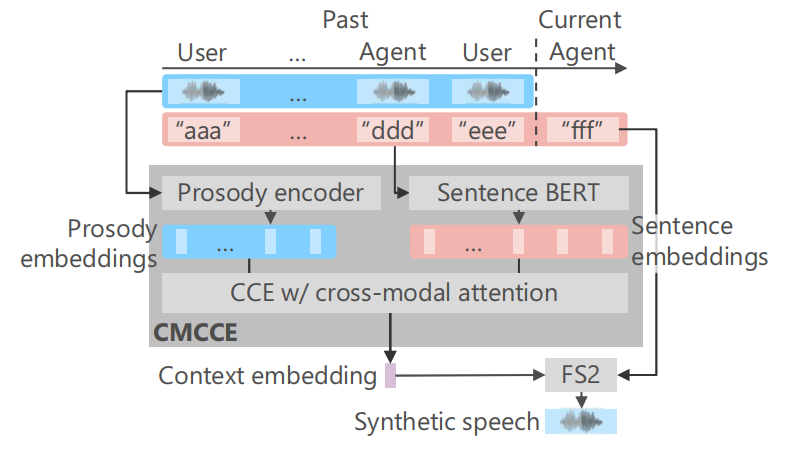
In the aspect of Multi-scale
However, a majority of developed conversational TTS systems all focus on extracting global information from history dialogue and omitting local prosody information. Prosody contains various context information and is efficient to enhance expressive of dialogue. Hence, besides utterance-level context information extracting, we additional adopt phoneme-level information extracting modules
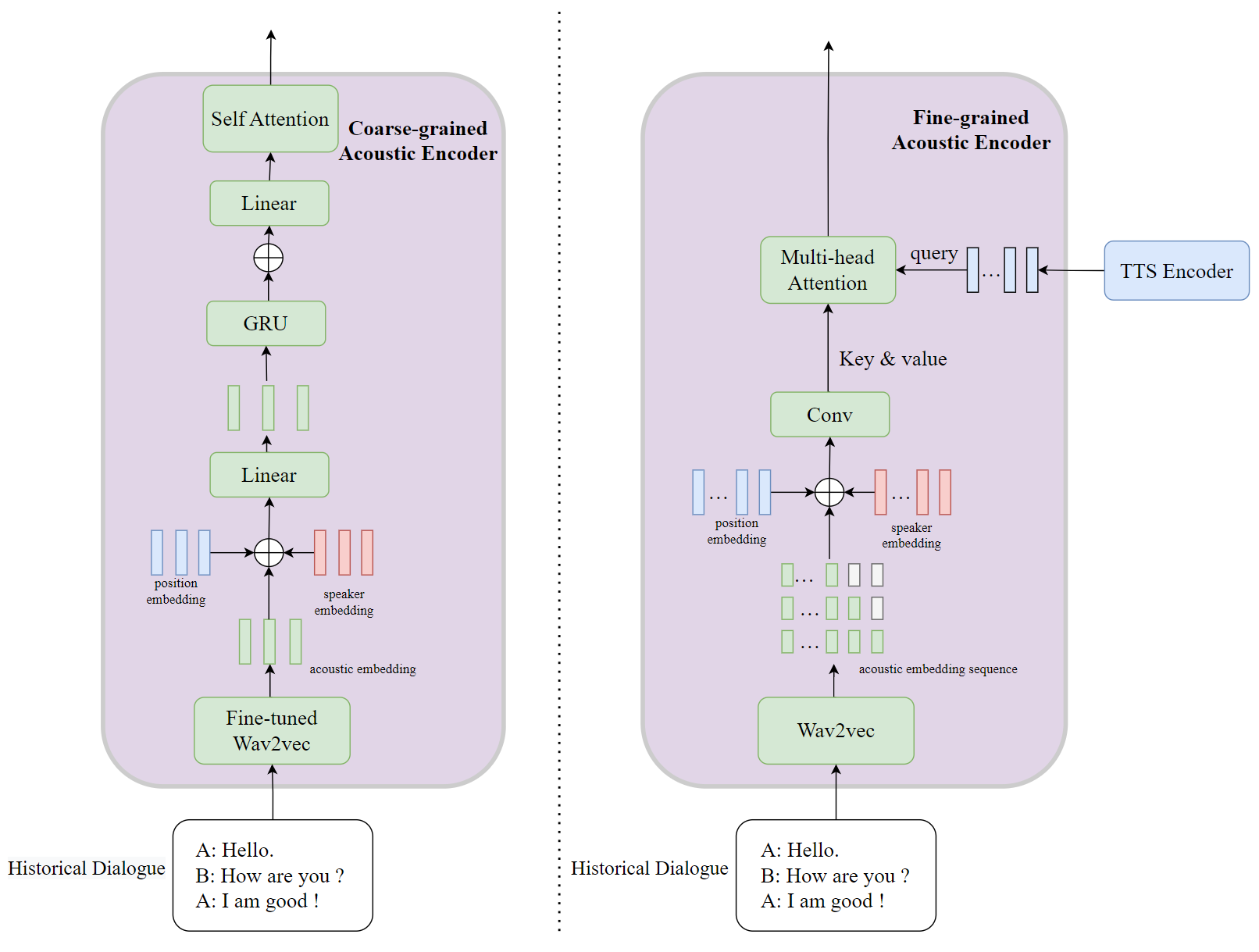
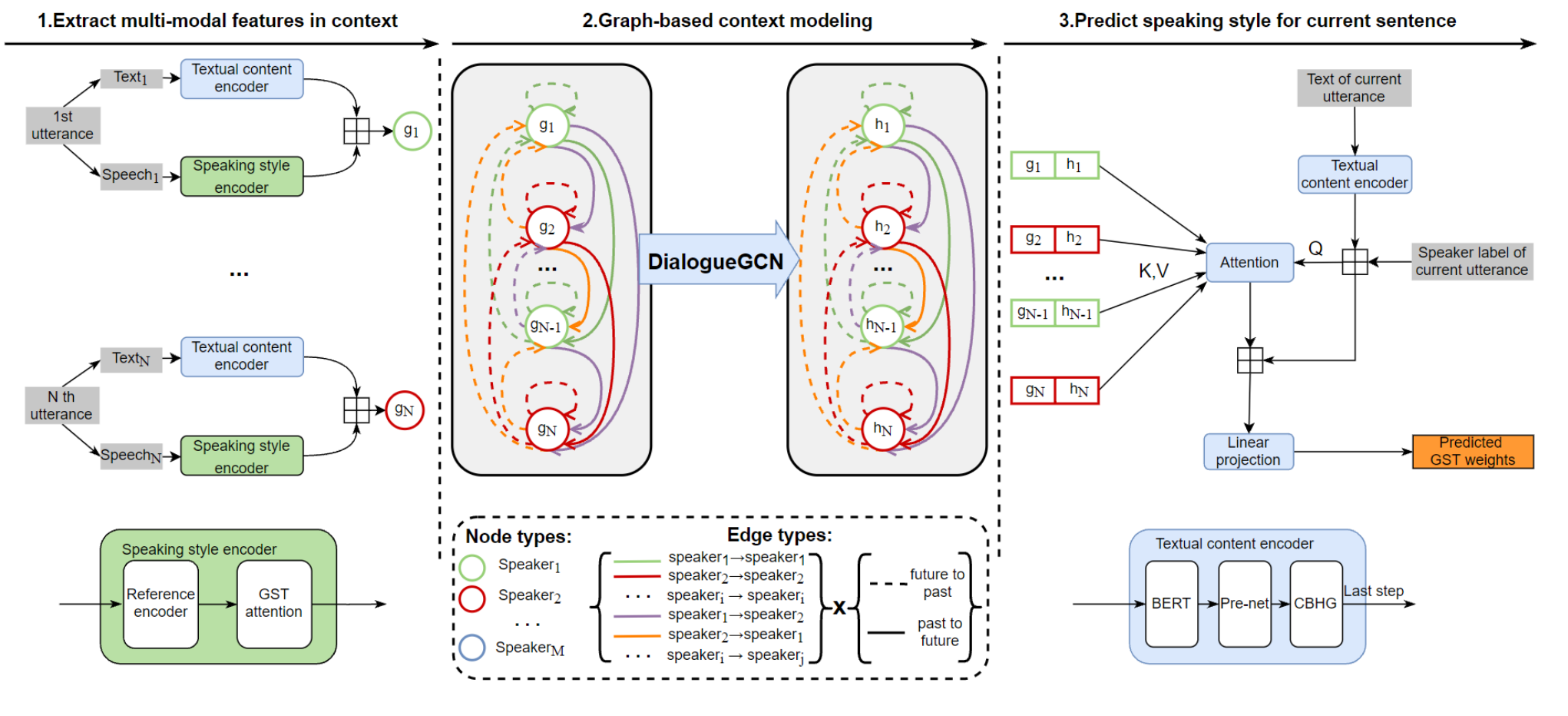
In the aspect of Multi-Modal
Only considering the textual context cannot directly affect the speech synthesis task and we found that the modality gap between them lead to marginal effect. Meanwhile, people speak in different tones even in the same contents or situations. Thus, modeling both modalities is significant.
The Whole Synthesis Model
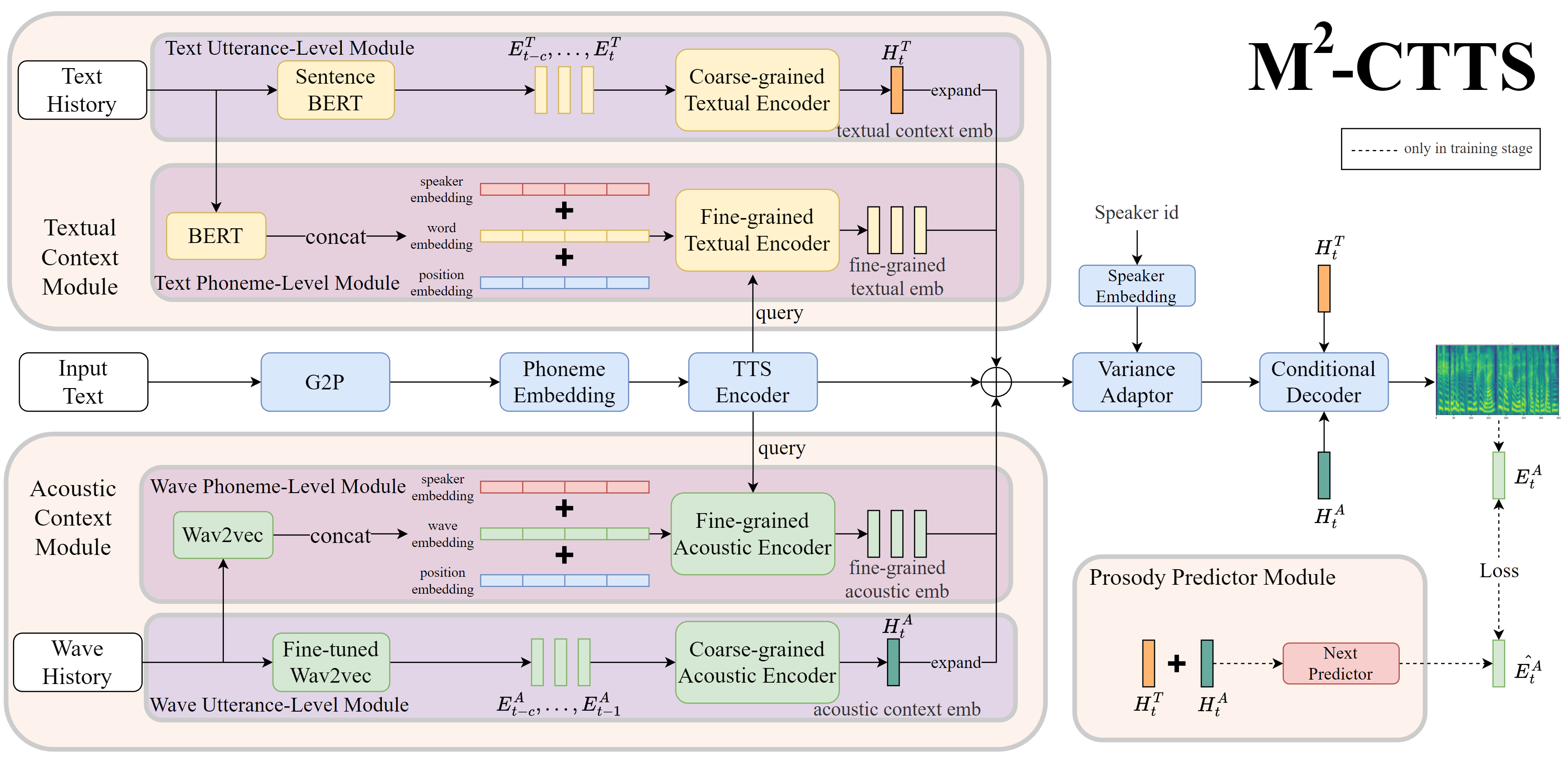
Example of Synthesized Speech
Here demostratie the synthesized speech by proposed method.
- Left: baseline FastSpeech2 model.
- Right: Proposed
Sample 1:
Sample 2:
Enjoy Reading This Article?
Here are some more articles you might like to read next: